HiGHCoOLS- Hierarchical Generative Hidden Convolutional Optimization System
This page describes the HiGHCoOLS astroinformatic project, a collection of python scripts that allow to perform deep learning experiments on large volumes of data with the Convolutional Neural Network (CNN; Lecun et al. 1989).
Release Notes
- Release currently available:
- Current release is 0.2, running on a stable platform, compatible with Python 3.7.x or higher, deployed at the end of March 2019.
Scope
DCGAN performs the data-augmentation through a Deep Convolutional Generative Adversarial Network (DCGAN), while Manipulation performs the more classical rotation, zooming vertical and horizontal flipping, dilatation and noise addition operations on the input images. For more information on the theoretical aspects of these data augmentation technique and their benefits, see Goodfellow et al. 2014 and Bengio 2009. Data Preparation transforms the input images (allowed types are .png, .jpg and .fits) in a form readable by our CNN (i.e. into a .pkl type file). In particular, this functional block is divided into two sub-functions: Automatic and User-driven. Automatic performs the training/test random shuffle and split of the input data, generating two .pkl files, easily recognised by their names (respectively, Test.pkl and Train.pkl). While User-driven transforms the user-provided data into a CNN readable .pkl file. The functional block Training handles the CNN training phase. This can be executed on a Graphical Processor Unit (GPU, enabled through the sub-function Parallel) or on the Central Processor Unit (CPU, enabled through the sub-function Serial).
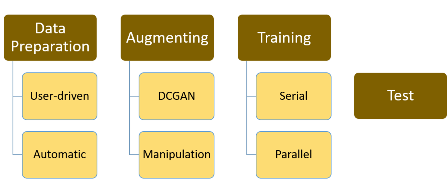
Given the current computational power of
modern GPUs, usually, the parallel execution is much faster
than the CPU one. Finally the Test functional block handles
the CNN test phase (once having performed the training
phase), providing a series of statistical estimates,
required to verify and validate the model training
performance on a blind subset of data.
These functional blocks can be combined together to compose
three main classification use cases, i.e. experimental flows
that, depending on the specific case, perform data
augmentation, prepare the data to submit to the CNN, and
perform the network training and test. Of course, an expert
user could combine the functional blocks to create much more
complex flows.
Documentation
- HiGHCoOLS User and Reference Manual
- Python package (upon e-mail request)

Copyright © 2010 DAME Collaboration. All right reserved.